Architecture
Cascaded QLoRA pipeline
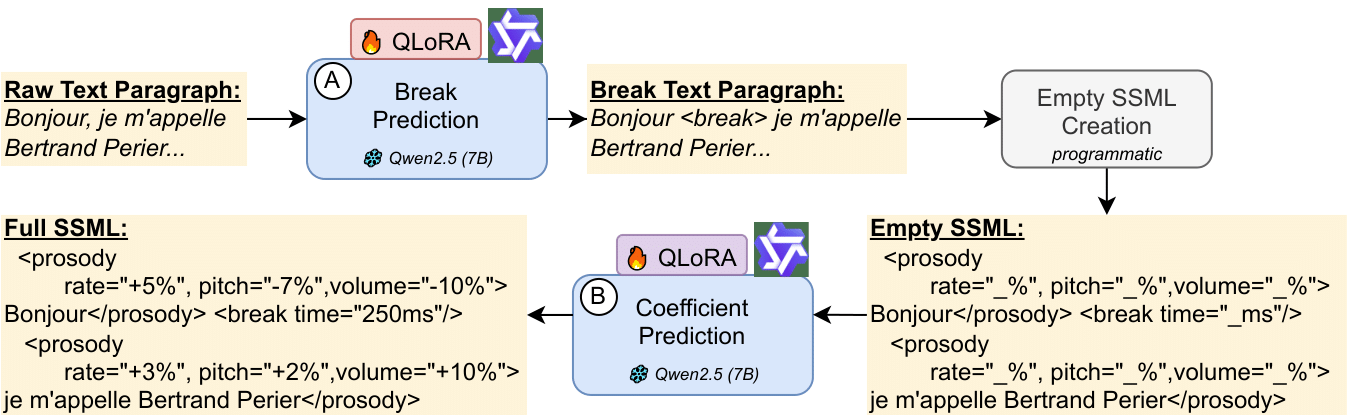
Raw French text → break annotations → SSML markup → expressive speech. Two fine-tuned Qwen-2.5-7B models in a cascaded inference setup.
Inference Pipeline
During inference, our system transforms raw French text into expressive speech through a cascaded approach:
- 01Text Input: Raw French text is processed for linguistic analysis
- 02Break Prediction: First QLoRA-tuned Qwen-2.5-7B model identifies optimal phrase break positions
- 03Prosody Prediction: Second model performs regression to predict SSML prosodic parameters (pitch, rate, volume)
- 04SSML Generation: Enhanced SSML markup is generated with optimized prosodic controls
- 05TTS Synthesis: Azure TTS processes the enhanced SSML to produce expressive speech
Qwen-2.5-7B
QLoRA ×2
Azure TTS
fr-FR-HenriNeural
14h French corpus
Training Data Preparation

Our models are trained using a comprehensive preprocessing pipeline that extracts prosodic features from a 14-hour French podcast corpus:
- Audio segmentation and transcription alignment
- Prosodic feature extraction (F0, energy, duration)
- Break annotation and prosodic target computation
- SSML parameter normalization for commercial TTS compatibility